ComfyUI-MotionDiff
ComfyUI MotionDiff将4DHuman、MotionGPT、MDM、MotionDiffuse和ReMoDiffuse集成到ComfyUI中。它提供多种安装方式。该产品能从4DHuman进行3D姿态估计,还可生成和渲染动作。输出两种火柴人:伪OpenPose(速度快但有局限)和真实OpenPose(效果好但需基于梯度优化)。可调整帧数、smplifiy_iters等关键参数。支持保存和加载SMPL数据,有节点用于保存为.pt文件、导出网格,以及从输入文件夹加载数据。
Fannovel16
Description
ComfyUI MotionDiff
将4DHuman、MotionGPT、MDM、MotionDiffuse和ReMoDiffuse集成到ComfyUI中
安装
在Ubuntu(可能也适用于其他Linux发行版)上安装先决条件
在终端中运行以下命令:
sudo apt-get install libglfw3-dev libgles2-mesa-dev freeglut3-dev
使用ComfyUI管理器(推荐)
安装ComfyUI管理器,并按照其中提供的步骤安装此仓库。
替代方法
如果您使用的是Linux系统或Windows上的非管理员账户,请确保/ComfyUI/custom_nodes和comfyui_controlnet_aux目录具有写入权限。
现在有一个install.bat文件。如果检测到是便携版,您可以运行此文件来安装软件。否则,将默认进行系统安装,前提是您已经按照ComfyUI的手动安装步骤进行操作。
如果您无法运行install.bat(例如,您是Linux用户),请打开CMD/Shell并执行以下步骤:
- 导航到您的
/ComfyUI/custom_nodes/目录。 - 运行
git clone https://github.com/Fannovel16/comfyui_controlnet_aux/。 - 导航到您的
comfyui_controlnet_aux目录:- 对于便携版/虚拟环境版本:
- 运行
path/to/ComfUI/python_embeded/python.exe -s -m pip install -r requirements.txt。
- 运行
- 对于系统Python版本:
- 运行
pip install -r requirements.txt。
- 运行
- 对于便携版/虚拟环境版本:
- 启动ComfyUI。
示例
基于4DHuman的3D姿态估计
- 视频演示:
- /examples/4dhuman.json
生成与渲染
有两种火柴人输出:伪OpenPose和真实OpenPose。伪OpenPose输出所需时间较少,但缺少头部、深度信息,并且不完全符合OpenPose格式。真实OpenPose输出总体上更好,但需要基于梯度的优化。一些重要参数:
- 帧数:要生成的帧数。目前所有模型都在HumanML3D上进行训练,这是一个20 fps的数据集。
- smplifiy_iters:将运动数据转换为SMPL过程中的优化迭代次数,类似于训练步骤。
- smplify_step_size:类似于学习率。对于相机平移优化,良好的损失值约为1到15;对于第二步,损失值约为1e+6到2e+6。您可以尝试减小步长并增加迭代次数,类似于训练过程。
- smpl_model:用于可视化的SMPL模型。仅对1.0.0模型(10个形状主成分)进行了测试。您可以将自己的模型(
.pkl文件,去除chumpy)放在ComfyUI-MotionDiff/smpl_models目录中。 - yfov:垂直视场角(以弧度为单位),类似于缩放的倒数。ChatGPT的解释如下:
以弧度为单位的浮点垂直视场角是指图形应用程序或游戏中垂直可视区域的角度。它决定了观察者可见的垂直空间范围。该值通常以弧度为单位指定,弧度是角度的一种度量单位。较大的值将导致更宽的垂直可视区域,而较小的值将导致更窄的垂直可视区域。
附注:当将SMPL渲染的深度图与ControlNet一起使用时,可能会生成半裸女性图像。理论上,模型已经从深度图中学习到了半裸模式。
保存和加载SMPL
- 截图:
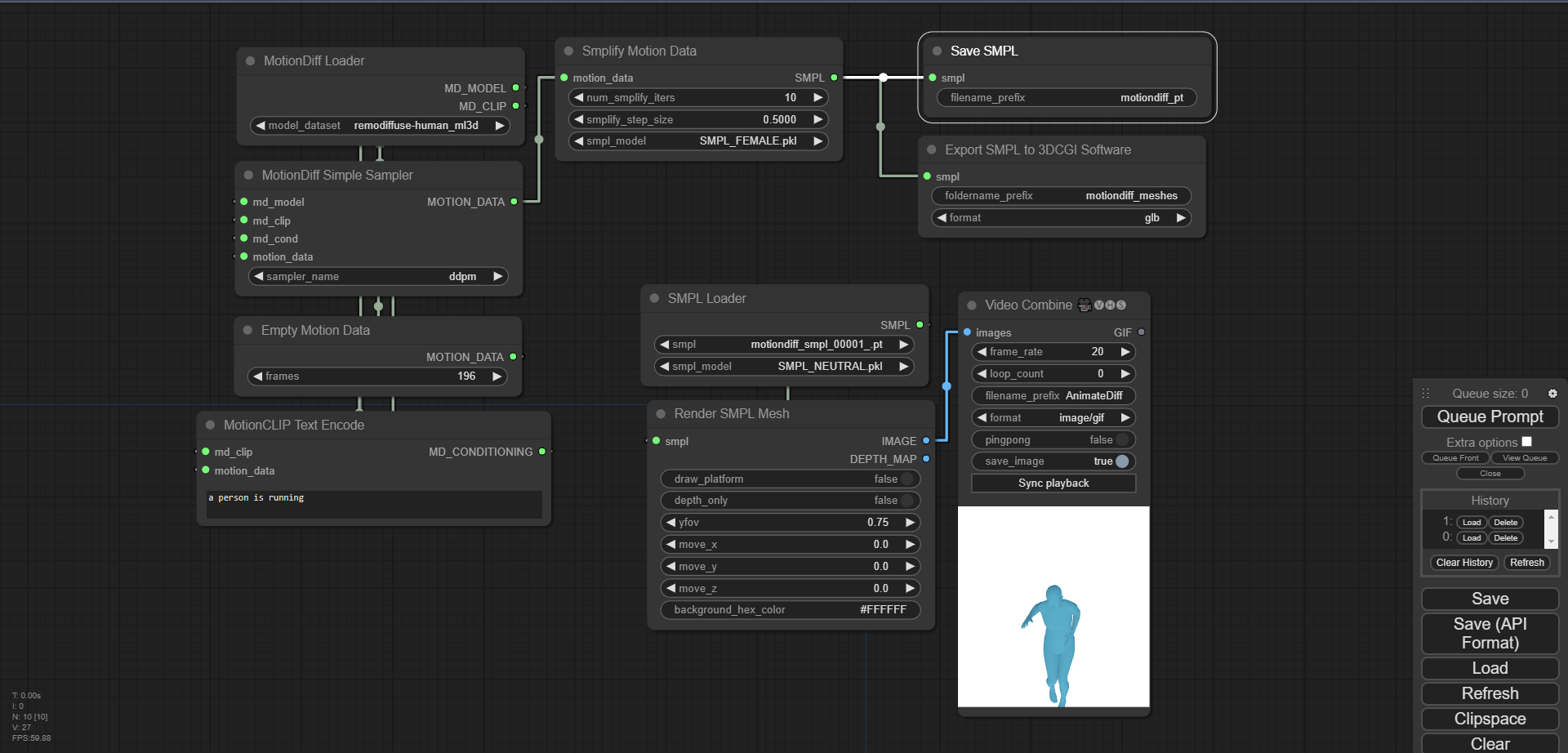
- 工作流json文件: save_and_load.json
保存SMPL节点将SMPL数据保存为.pt文件。
将SMPL导出到3DCGI软件节点将网格保存到一个文件夹中,其中包含可以导入到Blender、虚幻引擎、Unity等软件的网格文件。
两个节点都将结果保存到Comfy的输出目录中。
加载SMPL节点从Comfy的输入目录中检索文件。您需要将.pt文件从输入目录复制到输出目录。