ComfyUI_ADV_CLIP_emb
This repo provides 4 ComfyUI nodes for more control over prompt weighting. The CLIP Text Encode (Advanced) node has two settings: 'token_normalization' with options like 'none', 'mean' etc., and 'weight_interpretation' including 'comfy', 'A1111' etc. It visualizes up - weighting methods and explains Compel's down - weighting. The Mix Clip Embeddings node is deprecated. For SDXL support, there are nodes like BNK_CLIPTextEncodeSDXLAdvanced with a 'balance' setting, BNK_AddCLIPSDXLParams to add SDXL parameters, and BNK_AddCLIPSDXLRParams to add refiner parameters.
BlenderNeko
Description
Advanced CLIP Text Encode
This repository includes 4 nodes for ComfyUI, which offer more control over how prompt weighting is interpreted. It belongs to the ComfyUI_ADV_CLIP_emb project, enhancing the capabilities of ComfyUI.
BNK_CLIPTextEncodeAdvanced Node Settings
To achieve this, a CLIP Text Encode (Advanced) node is introduced with the following two settings:
Token Normalization
This setting determines how token weights are normalized. Currently, it supports the following options:
- None: Does not modify the weights.
- Mean: Shifts the weights so that the mean of all meaningful tokens becomes 1.
- Length: Divides the token weight of long words or embeddings among all the tokens. It does this in a way that the magnitude of the weight change remains constant for different token lengths. For example, if a word is represented by 3 tokens and has a weight of 1.5, each token gets a weight of approximately 1.29 because sqrt(3 * pow(0.35, 2)) = 0.5.
- Length + Mean: Divides the token weight of long words and then shifts the mean to 1.
Weight Interpretation
This setting determines how up/down weighting should be handled. Currently, it supports the following options:
- Comfy: The default in ComfyUI. CLIP vectors are linearly interpolated (lerped) between the prompt and a completely empty prompt.
- A1111: CLIP vectors are scaled by their weight.
- Compel: Interprets weights similarly to compel. Compel up-weights in the same way as Comfy but mixes masked embeddings to achieve down-weighting (more on this later).
- Comfy++: When up-weighting, each word is lerped between the prompt and a prompt where the word is masked out. Additionally, it uses Compel-style down-weighting.
- Down Weight: Rescales the weights so that the maximum weight is 1. This means that you will only be down-weighting. It uses Compel-style down-weighting.
Intuition Behind Weight Interpretation Methods
Up Weighting
The diagram below visualizes the three different ways to transform the CLIP embeddings for up-weighting:
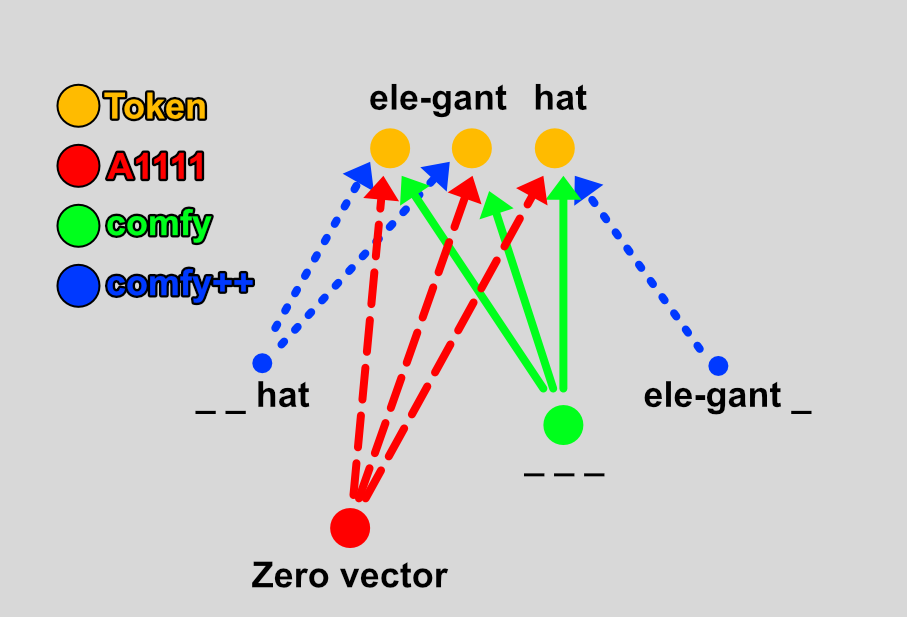
As shown, in A1111, we use weights to move along the line between the zero vector and the vector corresponding to the token embedding. This can be seen as adjusting the magnitude of the embedding, which makes our final embedding point more in the direction of the thing we are up-weighting (or away when down-weighting) and creates stronger activations in StableDiffusion (SD) due to the larger numbers.
Comfy also creates a direction starting from a single point but uses the vector embedding corresponding to a completely empty prompt. We are now moving along a line that approximates the essence of a certain thing. Although the magnitude of the vector does not increase as fast as in A1111, this method is actually quite effective and can cause SD to aggressively pursue up-weighted concepts.
Comfy++ does not start from a single point but moves between the presence and absence of a concept in the prompt. Although the idea is similar to Comfy, it is less aggressive.
Visual Comparison of the Different Methods
Below is a short clip of the prompt cinematic wide shot of the ocean, beach, (palmtrees:1.0), at sunset, milkyway, where the weight of palmtrees gradually increases from 1.0 to 2.0 in 20 steps. (Made using silicon29 in SD 1.5)
Down-Weighting
One issue with using the above methods for down-weighting is that the embedding vectors associated with a token do not only contain "information" about that token but also pull in a lot of context from the entire prompt. Most of the information they contain seems to be about the specific token, which is why these up-weighting interpretations work. However, the given token permeates the entire CLIP embedding. In the example prompt above, we can down-weight palmtrees to 0.1 in Comfy or A1111, but because the presence of the tokens representing palmtrees affects the entire embedding, we still see many palmtrees in the output. Suppose we have the prompt (pears:.2) and (apples:.5) in a bowl. Compel does the following to achieve down-weighting: it creates embeddings
A=pears and apples in a bowl,B=_ and apples in a bowlC=_ and _ in a bowl
It then mixes these into a final embedding 0.2 * A + 0.3 * B + 0.5 * C. This way, we only have 0.2 of the influence of pears and 0.5 of apples in the entire embedding.
Mix Clip Embeddings Node (Deprecated)
The functionality of this node can now be found in the core ComfyUI nodes.
SDXL Support
To support SDXL, the following settings and nodes are provided. Note that the CLIP Text Encode (Advanced) node also works well for SDXL in the ComfyUI_ADV_CLIP_emb project.
BNK_CLIPTextEncodeSDXLAdvanced
The CLIP Text Encode SDXL (Advanced) node provides the same settings as its non-SDXL version. In addition, it has two text fields to send different texts to the two CLIP models and the following setting:
- Balance: A trade-off between the CLIP and openCLIP models. At 0.0, the embedding only contains the output of the CLIP model, and the contribution of the openCLIP model is zeroed out. At 1.0, the embedding only contains the openCLIP model, and the CLIP model is entirely zeroed out.
This node is mainly for experimentation.
BNK_AddCLIPSDXLParams
The Add CLIP SDXL Params node adds the following SDXL parameters to a conditioning:
- Width: The width of the image crop.
- Height: The height of the image crop.
- Crop W: The left pixel of the crop.
- Crop H: The top pixel of the crop.
- Target Width: The width of the original image.
- Target Height: The height of the original image.
BNK_AddCLIPSDXLRParams
The Add CLIP SDXL Refiner Params node adds the following refiner parameters to a conditioning:
- Width: The width of the image.
- Height: The height of the image.
- AScore: The aesthetic score of the image.